Transformers are the backbone of modern AI models like GPT, Claude, Llama, and Gemini. Their core idea is straightforward: language only makes sense when you understand how words relate to each other.
A transformer begins by turning each word into a vector that captures meaning — “coffee” sits closer to “tea” than to “mountain,” “king” sits near “queen,” and so on. These embeddings give the model a foundation for comparing concepts.
Instead of reading text word by word, transformers look at entire sentences at once. This lets them identify long-range connections. In a sentence like “The boy who came yesterday forgot his bag,” the model uses attention to connect “his” with “boy,” not with “yesterday.”
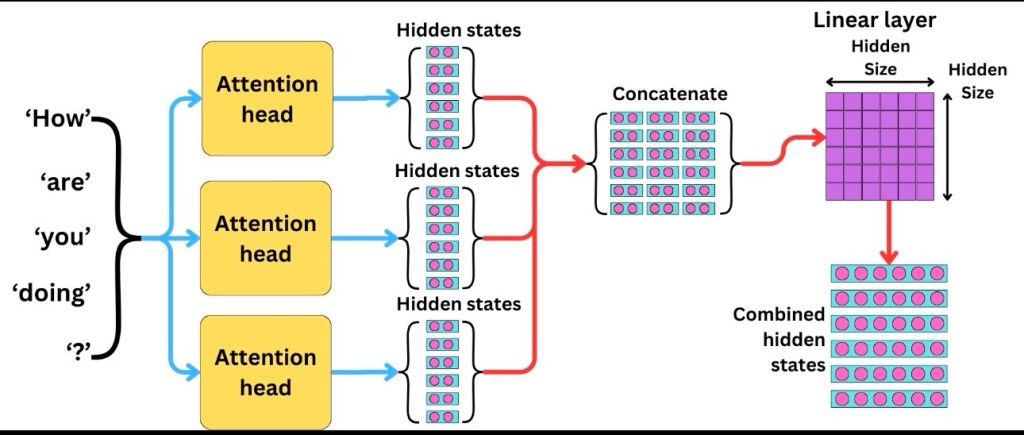
Language has many layers — grammar, description, tone, reference — so transformers examine text through multiple attention heads. Each head focuses on a different angle, and stacked layers refine the understanding step by step.
In the raw input, a word like “bank” is ambiguous. After passing through a transformer, that ambiguity is resolved. The internal representation becomes different for “river bank” than for “money bank.” This transformation happens gradually, layer by layer, through attention and feed-forward steps. By the end of the process, the model has turned:
(1) plain token embeddings → (2) contextual meaning representations → (3) usable outputs, such as the next word, a summary, or a translation.
So A transformer is a neural network architecture designed to transform a sequence of inputs into a more meaningful sequence of representations. It doesn’t transform one language into another by default — it transforms each word (after being converted into numbers) into deeper, more accurate vectors that reflect its meaning in context.
Transformers come in three shapes:
Encoder (built for understanding; e.g., BERT)
Decoder (built for generation; e.g., GPT, Llama, Claude)
Encoder-Decoder (built for structured input→output tasks; e.g., T5)
Most large language models today use decoder-only transformers, because predicting the next word scales extremely well and leads to broad general capabilities.
You can see the whole design in action with a simple prompt:
“Ravi forgot his umbrella because…”
The model doesn’t retrieve a stored fact — it predicts the next most natural continuation based on relationships it has learned:
“…he left in a hurry.”
“…the weather changed suddenly.”
One word at a time, guided by learned patterns.
That’s the transformer in practical terms — an architecture built on meaning, relationships, and refinement — and the foundation behind the AI systems we use every day. Without transformers, We would still be stuck with old recurrent networks that could only handle short sentences like “This is good/bad” and nothing more. Everything from long-context reasoning to multimodal understanding to code generation directly depends on the transformer — without it, the entire modern AI ecosystem simply wouldn’t exist.

Leave a comment